Just a quick disclaimer – I don’t intend on getting too technical with databases. The target audience for this article is still your everyday office worker rather than a database administrator or IT professional.
What is a database?
A database stores and organizes digital information. The way data is organized within the database allows it to be specialized for different scenarios. This results in different types of databases.
A transactional database is organized to be easily filled with data or have its data retrieved. Transactional databases are used as the backend for applications where the user is entering data into forms. Sometimes these databases are referred to as Online Transaction Processing Databases (OLTP databases).
An analytical database is organized to quickly provide answers to questions that require aggregation. Examples of queries sent to this type of database might be “Sales by Customer by Year and Month”. The database then quickly aggregates the sales amounts and then groups them by all combinations of Customer, Year, and Month. While great at handling these types of queries, this kind of database isn’t optimized for handling multiple small transactions (updates or insertions). Because of this, users generally do not enter data from an application straight into the database. Instead, an analytical database usually sources its data from a transactional database. Sometimes these databases are referred to as Online Analytical Processing Databases (OLAP databases).
Why learn about database types?
The point of this blog is to help you understand how business intelligence systems work and hopefully show you how to build your own to share with others. The most important skills required are how to create an analytical database, rather than a transactional one. However, because most analytical databases are fed from transactional databases, it’s also important to understand how a transactional database is organized, so for now let’s start with transactional databases.
What does a transactional database “look” like?
It’s essentially a collection of tables. Each column in the table corresponds to an attribute, and each row corresponds to a record. Records are things and attributes are information about the things. It’s a natural way of organizing information. For example, imagine you were recording a classroom’s attendance: you’d have one column for the names of students and another column for whether they were present, which could be noted as true/false values.
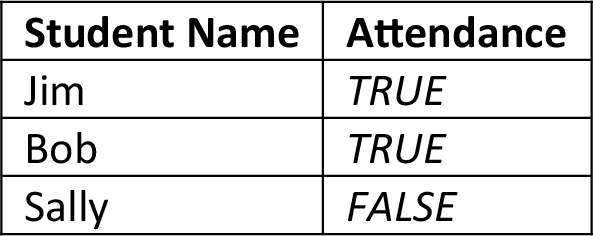
Another more standard example of recording transactions would be sales transactions.Silly Sally seems to be skipping school.
What is a sales transaction?
A sales transaction is a regularly occurring event that has many pre-defined attributes such as the customer, date, product, quantity, and price. If you were to start recording this information in a spreadsheet you’d set up a table that looks something like this:

The way this is organized is that each attribute goes into a column (or “field” as some call it), and each row then becomes a single transaction (apart from the top row, which contains headers).So far so good. John Doe bought 1 soccer ball on January 1st for $20.
As you have more sales transactions your table then gets taller and taller. Because each transaction will always share the same number of attributes, there is no need to change the number of columns unless you decide to collect new types of information.
It’s probably worth pointing out that I think all information should be collected this way. If you ever want to gather information from people on a regular basis, for the love of god please just use a table with columns as types of information and rows as records of information. Once you’ve collected your info you can then build a summary report on top of the data. Please don’t get people to enter data directly into things that look like reports.
OK enough of that, on to the next question.
Where do the customer details go?
In your sales transaction there are probably a lot of details about the customer that you want to record, do you just add another column for their address? And middle name? And phone number? And email? And credit card details… and on and on.
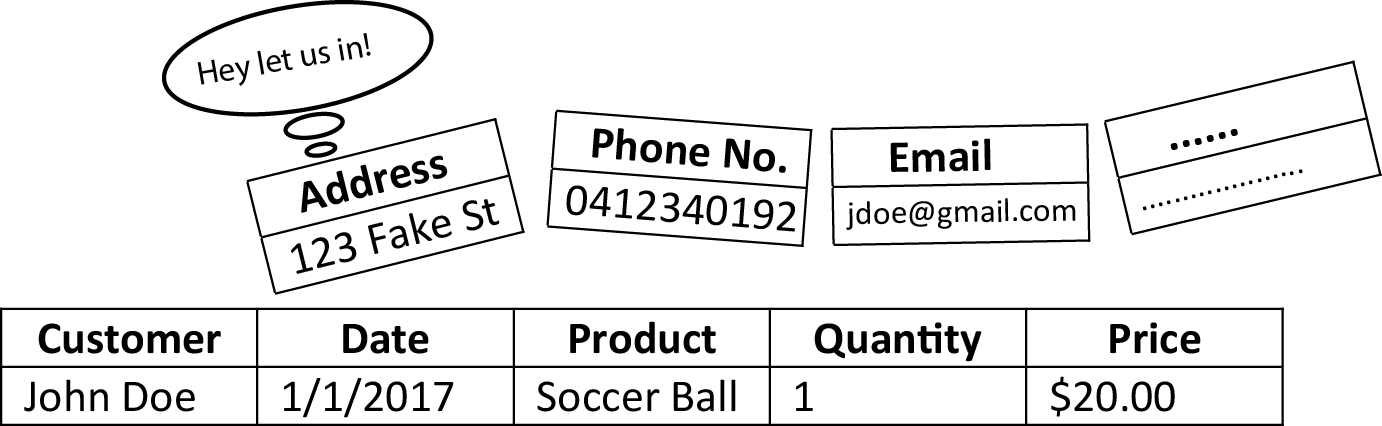
I think you see my point.
Very quickly you’ll start to get a large table with most of the columns just being exactly the same for each transaction. You want to record the customer’s phone number somewhere but do you really need to record their phone number every time they buy something? It’s not like they’ll change it very often.
So what should you do to record customer details then? Instead what you do is have a separate Customer table and then link that to your existing SalesTransactions table.
How do you link the two tables together?
It might seem like a trick question involving some outside system or special technology for linking tables, but in reality all you have to do to link your customers to their transactions is to reference the Customer in the SalesTransactions table by adding a column for the customer ID.
Why a customer ID (also sometimes called a key) instead of the customer name? The answer is simple, what if you have two John Smith’s? How will you know which John Smith is the one who made the transaction?
In summary, each customer then has this unique ID (often called a key) that can be easily searched and will never result in a duplicate being found. In fact, every single table in your database will have a “key” column that identifies each row in its table.
Because both the Customer and SalesTransactions tables have a matching CustomerID value, you can relate them together. Think of an operation similar to a VLOOKUP in Excel. If you recorded post/zip codes in your customer table, it’d then be trivial to group your sales amounts (which is just the sum of the quantity of goods sold multiplied by their price) by these post codes to see which neighbourhoods most of your customers come from.
The key that identifies rows within its own table is called the primary key. In our example above the Customer ID within the Customers table would be referred to as the primary key. A key that references a table outside of the existing table is called a foreign key. In the example above this is the Customer ID within the SalesTransactions table.
Why split out the customer details into a separate table?
Now, you don’t HAVE to split out these customer details from your sales transactions table, but the real advantage of separating them out is that your database becomes much smaller than it otherwise would have been.
As well as this, it allows you to link the same CustomerID from your Customer table to any other set of tables. What if your customers want to send back their broken sports equipment? You’d issue an RMA (Return-to-Manufacturer-Authorization) and likely record it in its own table, with one of the columns in that RMA table referencing the customer ID. So not only do you save the space from just your sales transactions table, but ALSO from any other table that will also link to your customers.
Another benefit is that maintaining accurate customer details then becomes very simple, you only need to update the single row in the customers table. Because the key never changes, your sales transactions and RMAs table will still refer to the correct record, but the details will have been updated.
One last thing… (Normalization)
You might want to go one step further when splitting up your information into different tables. The reason for this is because everyone wants their applications to be as fast as possible and take up as little space as possible. Remember our SalesTransactions table from above? Well actually some of this information is shared across the single sale. (I’ve swapped out the customer’s name and product name with IDs aka keys as well as added a SaleID field).


See how the CustomerID and Date columns are the same for this sale because it happened at the same time?What happens if a customer buys more than one product? Naturally you would just add another row with the second product and respective quantities.
It turns out you can save even more space in your database by further separating out your SalesTransactions table into a Sales and SalesLines table (let’s drop the clunky “transactions” from our table name).
All information unique to the whole sale is recorded in the Sales table. This will include things like the customer and the date.
The items bought (because there will be many) will be in their own SalesLines table. This table will then reference the Sales ID, and list details such as the product ID, the quantity, unit prices, discounts, and possibly also some calculated fields (such as extended price).
This practice of splitting up your tables is so common that it’s called “normalization”, or “normalizing your tables”. This is done for just about every type of transactional database. The benefits of doing it are that every time you want to add a row to a table there are fewer columns so each row you insert contains less data. As well as this, the total number of “cells” in your database is much lower than having very large, flat tables.
Summary
Ok so we’ve briefly covered the basics of transactional databases. They’re just a collection of tables that are related to each other by referencing the key of another table. Each row in a table has a unique key that identifies it. This key in its own table is called a primary key. Any key that is used as a reference to another table is called a foreign key. When organizing data it’s important to split out different entities from one another (i.e. split customers and sales into separate tables). This makes your database smaller and reduces the workload of any one transaction, in effect making your database more efficient. This “normalization” of tables goes one step further where you should also split up entities into multiple tables to reduce duplicate recording of information (i.e. only record the date for a sale once, rather than against each product sold on the same transaction).
So that’s it for the basics of OLTP (transactional) databases. Read on to learn more about OLAP (analytical) databases. OLAP databases are the kind that power most business intelligence applications.
