Disclaimer: With the release of additional external tools such as Tabular Editor, ALM Toolkit, and DAX Studio there is less usage of Visual Studio.
It’s time to meet the new tools! If you missed the introduction explaining why you might want to use these tools, check out my last post here.
I hope you like the illustrations, I decided to make some custom ones myself because the Power Query and Power Pivot icons are different depending on which application you use them in (even though they are the same tool!).
Before we get started it is worth reiterating that point – you can use Power Query and Power Pivot in three applications: Excel, Power BI Desktop, and Visual Studio 2015 (via SQL Server Data Tools) to deploy to SQL Server Analysis Services vNext.
No one really likes walls of text so I decided to try out my illustration skills and create a diagram of what I think the basic steps of performing business intelligence look like using Microsoft’s new self-service BI toolset.
Have a look at the below and I’ll explain the illustration in the following paragraphs.

There’s quite a lot of info in that graphic so let’s break it down. The basic steps are: e
- Create your data (text files, databases, workbooks, etc.)
- Extract and transform your data (Power Query)
- Model your data (Power Pivot)
- Present your data (Excel / Power BI / SQL Server Reporting Services
0. Creating data

I’ve labelled “Creating Data” step 0 because it isn’t really a “step” that you follow, and unless you’re designing a new process from start to finish you won’t be doing a whole lot of this. That being said, it is useful to know how to set up your data collection to enable easier reporting in the future. I hope to eventually go through some tools that can help with this – namely Excel, PowerApps, Access, and if I’m super keen maybe I’ll eventually get into creating a Universal Windows Platform (UWP) database app.
1. Extracting and transforming data (Power Query)

Moving on, both step 1 and 2 (connecting, transforming, and modelling) were initially done within Power Pivot when it released around 2010, but demand for better connectivity and powerful transformation capabilities soon meant that a better solution was needed, this is where Power Query comes in.
You can use Power Query in Excel, Power BI, and recently (as of December 2016) you can also use it in Visual Studio via SQL Server Data Tools (SSDT) when developing for SQL Server vNext (i.e. the version of SQL Server after 2016).
Power Query aims to let you connect to all of your data sources, whether they’re text files, Excel workbooks, CSV files, or all kinds of databases. Once you’ve connected to your data, you can perform simple manipulations – such as removing columns, or heavy duty transformations – such as un-pivoting. You can also flatten and de-normalize tables to change the schema from snowflake-schema to star-schema to make modelling in Power Pivot simpler and improve your calculation efficiency (more on this later).
Most people use Power Query by pressing buttons in the rich user interface that then performs the transformations they want. Every time you perform a transformation it automatically creates the formula in Power Query Formula Language (PQFL), and adds it as a step to the query pane on the right hand side. In reality each set of button presses adds on a new formula line to create one large formula, with each new “step” just referencing the last one. The full query formula can be viewed within the “Advanced Query Editor”. More on all of this later.
After you’ve performed all the transformations you need and have a nice set of clean tables, you can load them into your data model.
2. Modelling data (Power Pivot)

Once your data model is loaded you can use Power Pivot to create relationships between your tables. This might involve linking the “Sales” table to the “Customers” table via a “CustomerID” column that exists in both tables.
The main reason these tables are separate is because it avoids duplicating data – rather than writing the full set of customer details into every transaction, you can just have a single reference in that sale record to the customer. This lets you have fewer columns in your sales transactions table and reduces the size of your model. I’ll probably write a topic about this in the coming days as it’s a fundamental aspect of database design called “normalisation” – in fact it’s so common that when people refer to a “normal’ database they mean one that has removed duplicate information (i.e. it has been “normalised”).
Once the relationships are created between tables, you then have to create the “measures” or calculations you want. These measures are written in the Data Analysis eXpressions (DAX), a formula language that’s very similar to Excel formulas. An example of a simple measure might be “Sales:= SUM( FactSales[Sales Amount])”. This DAX formula sums up all of the sales amounts for each row in your Sales table. In reality your Sales table might have extra columns (fields) that determine if the sale was a deposit, a credit, a partial payment, etc. This means you’ll likely have to write slightly more complicated measures to filter only the rows you want.
Similar to the Power Query Formula Language, there are entire books dedicated to the topic of writing these DAX formulas.
3. Presenting Data (Excel / Power BI / SQL Server Reporting Services)
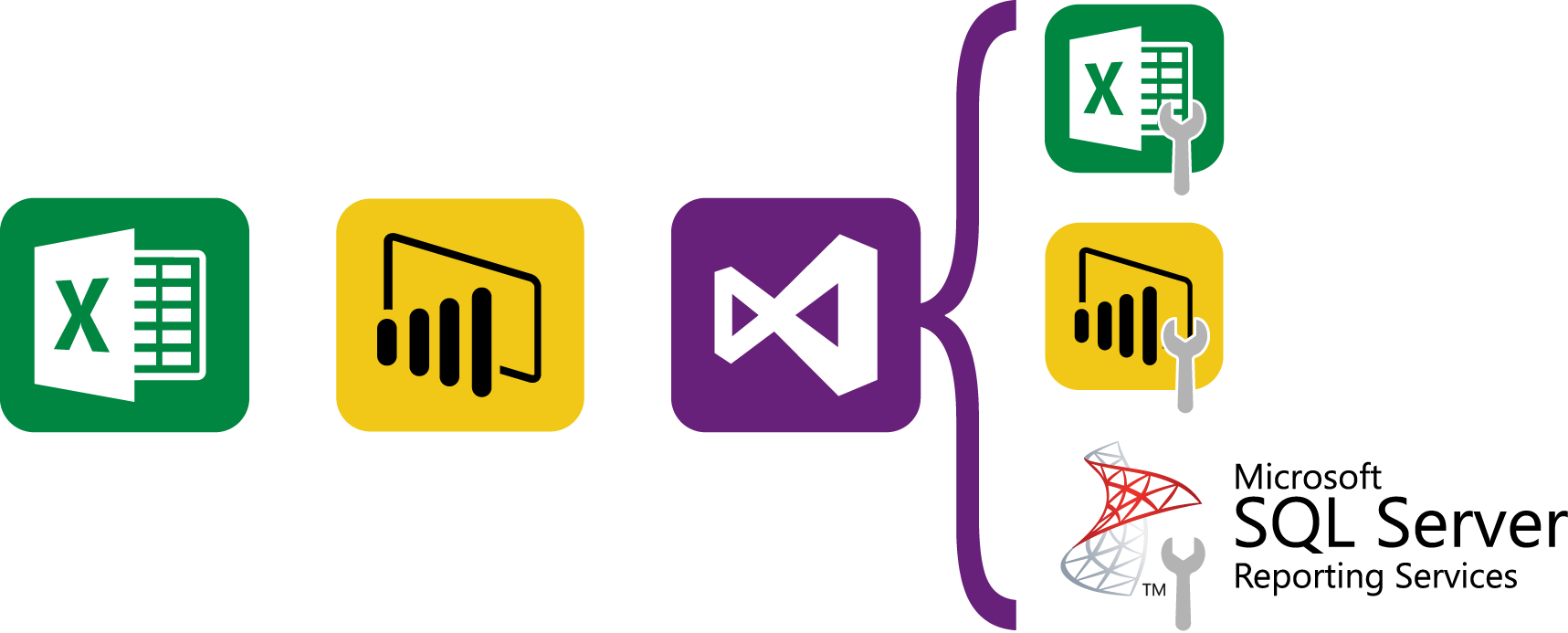
Finally, for the last step of “Presenting Data” you can see that there are a whole host of options at your fingertips depending on whether you’ve used Excel, Power BI, or Visual Studio to create your model. Depending on which application you’ve used to create your model, there are also many options on how you want your users to interact with it.
Excel
The simplest solution is just to use Power Query and Power Pivot within Excel and then send the workbook to your user. If the user has access to the data sources then they can also refresh the workbook when the data sources get updated (by going into the Data tab and hitting “refresh”), otherwise they’ll have to rely on you sending them an updated workbook. If you create any new measures or edit the Power Query transformations, then you’ll also have to send an updated workbook.
Power BI
The initial solution to this is to instead use Power BI to create your model yourself, upload it to the cloud and refresh the data yourself on a schedule, and then let others view the reports either online, on mobile, or via the Excel connector. It’s a fairly elegant solution except that there can often be long refresh times when linking Excel to the online tabular model. As well as this, you might decide you want to split your Power BI files into different departments to avoid it getting too bloated. This means you’ve suddenly got different files that need to be maintained, especially if you edit any of the common dimensions (e.g. your “Organizations” table might be used for both sales and purchases).
Visual Studio for SQL Server Deployment
The eventual solution to managing multiple models and improving response times is to use Visual Studio to create your model and then deploy it into SQL Server Analysis Services. Once deployed into Analysis Services you can connect to your model from Excel, Power BI, or SQL Server Reporting Services. This gives you a lot of flexibility when presenting your data and it also means that you can manage the data model from within one centralised location (Visual Studio).
Other advantages are advanced security features so that different users “see” different parts of the model based on either Windows Authentication (i.e. what they use to log in to their work computer) or anonymous authentication (custom login/password combinations). Queries can also be broken down into more manageable pieces via partitions, and because it deploys to SQL Server you can use the SQL Agent to routinely refresh and re-deploy the model.
Currently unavailable in SQL Server vNext but certainly on the way is the ability to have DirectQuery models that connect live to the datasources, removing the requirement for any scheduled refreshes. Note, however that this is a strictly SQL Enterprise Edition feature only.
What’s next?
Now that you’ve got the bird’s eye view there are just a few more housekeeping items left until it’s time to develop models.
See here for a quick primer on the differences between PQFL (Power Query Formula Language, in Power Query) and DAX (Data Analysis eXpressions, in Power Pivot).
See here on where to get access to Power Query, Power Pivot, and any other applications you might need when starting to develop a model.
